
こんにちは、ちゃりおです。
以前、ECSのスロットリング(設定に不備がありタスクが起動せず、startとstopを繰り返す)事象が発生しました。
事象に気づくことができず、NATGWを経由していたためECRからのimage pullで料金が大変な事になりました。
CloudwatchAlarm+ContainerInsight+MetricMathを使用して、ECSのスロットリングを検知する方法を紹介します。
ECSのスロットリング検知
デモ用のCDKを作りました。
実行すると、ECSからアラートまで作成されます。
作成されたリソースを見てみると、わかりやすいと思います。
ContainerInsightでRunningTaskCountとDesiredTaskCountを取得する
新しいタスクが正常に起動出来ないと、起動停止を繰り返します。
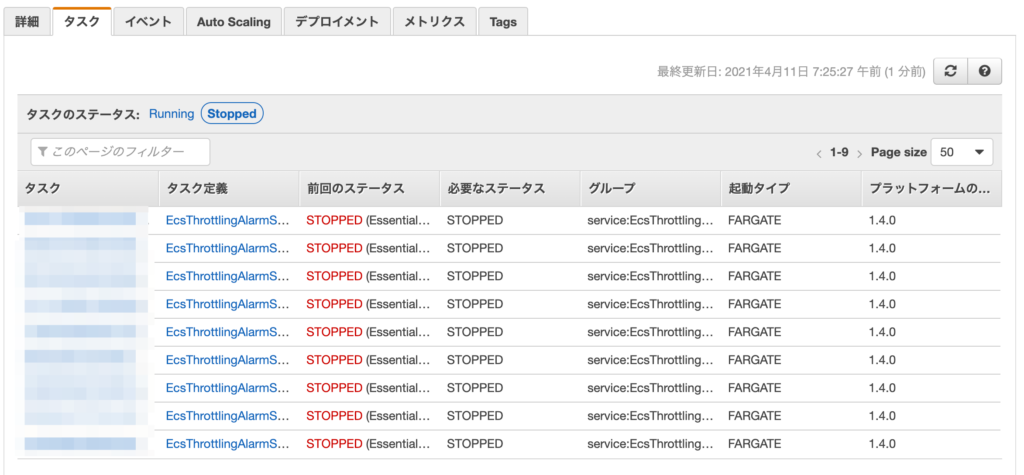
そのため、事象発生時は起動しているタスク数(RunningTaskCount)と必要なタスク数(DesiredTaskCount)が異なる状態になります。
デプロイ時など異なる状態になりますが、長時間続けば事象が発生している可能性があります。
そこで、「RunningTaskCount」と「DesiredTaskCount」を取得したいわけですが、標準のメトリクスでは提供されていません。
ContainerInsightを有効化する必要があります。
既存のクラスターに有効化したい場合は、以下のコマンドで出来ます。
$ aws ecs update-cluster-settings --cluster --settings name=containerInsights,value=enabled 有効化できるとカスタムメトリクスとして、「ECS/ContainerInsights」が作成されます。
クラスターおよびサービスレベルの Amazon ECS でメトリクスの Container Insights の設定
MetricMathでRunningTaskCount/DesiredTaskCountのメトリクスを作成
ContainerInsightを有効化して、メトリクスが取得できたら検知する用のメトリクスを作成します。
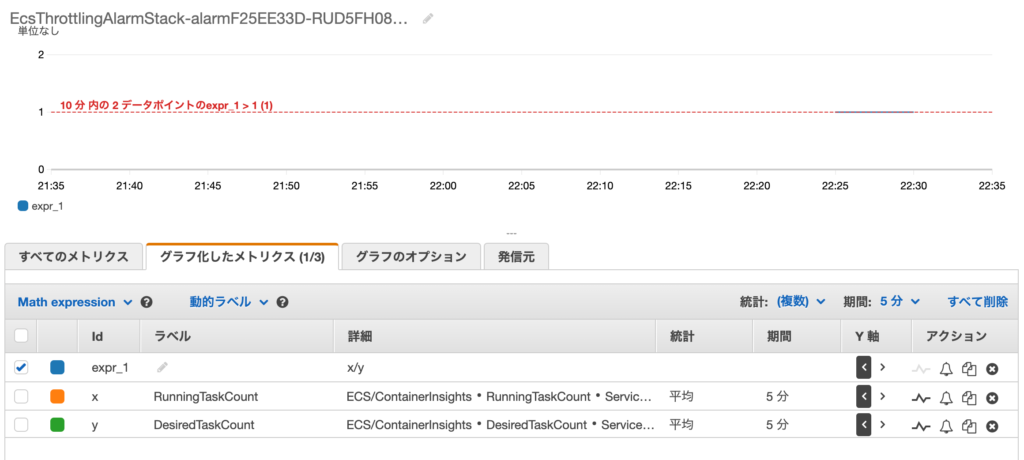
CloudwatchのMetricMathを使用すれば、メトリクスとメトリクスを計算して新しいメトリクスを作成することが出来ます。
今回は「RunningTaskCount」と「DesiredTaskCount」の差を知りたいので、「RunningTaskCount/DesiredTaskCount」でメトリクスを作ります。
正常時はタスク数に差がないので、1になるはずです。
CloudwatchAlarmで検知する
作成したメトリクスに対して、CloudwatchAlarmを設定して異常時に通知されるようにします。
デモにあるfailTaskだと一瞬start状態になって失敗します。その場合は、作成したメトリクスが1を上回ります。
逆にネットワークの問題(ECRに接続できない)などで、start状態にならずににstopになる場合は1を下回ります。
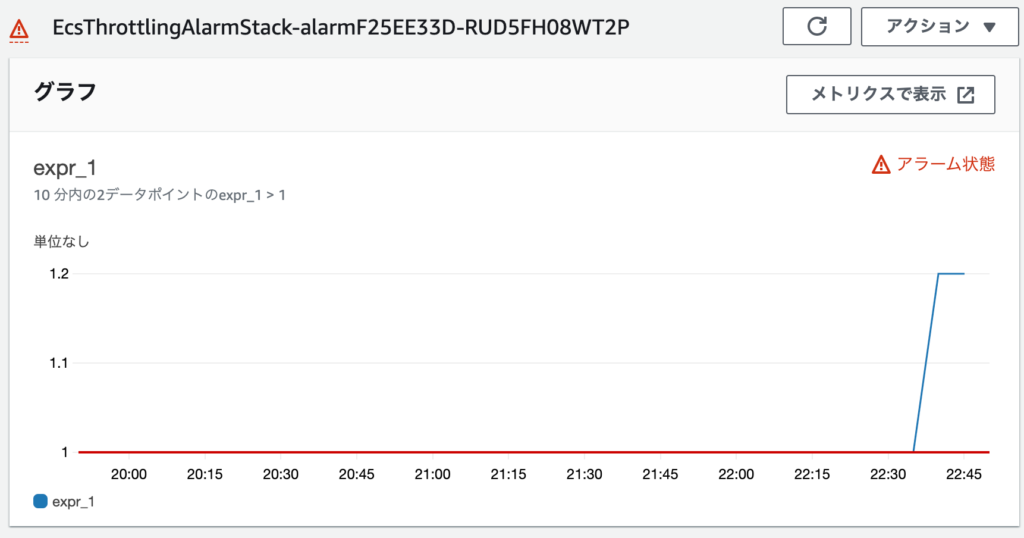
そのため、1以上と1以下のアラームを作成すれば良いと思います。
デプロイの頻度によっては検知してしまう可能性があるので、検知までのデータポイントの調整が必要かもしれません。
まとめ
ECSのスロットリングの検知についてでした。
ContainerInsightのおかげで、Lambdaを書くことなく実現できました。
カスタムメトリクスで料金がかかってしまうため、高くなりそうだったらLambdaを使う方法もいいかもしれません。






