
JAWS DAYS2021で「1年間運用して分かったCDKアンチパターン」というタイトルで登壇させていただきました。
発表内容と登壇レポートです。
発表概要
CDKは、プログラミング言語でインフラを定義できる便利なツールです。
しかし、自由度が高いゆえに書くことや運用の難しさがあると思います。
2020年前半ごろから、1年近くCDKで本番環境の運用を行いました。
実際運用してみて、アンチパターンを色々踏み抜いてきました。
CDKのメリット・デメリット、踏み抜いたアンチパターン、運用時に気をつけたほうがいいことについてお話します。
CDKを導入予定の方や、すでに運用している方の参考になればと思います。
対象者
CDK初心者向けの内容になっています。
- CDK,IaCに興味がある方
- CloudFormationから他のツールへ乗り換えを検討している方
発表資料 1年間運用して分かったCDKアンチパターン
https://speakerdeck.com/msato/jaws-days2021-1nian-jian-yun-yong-sitefen-katutacdkantipatan
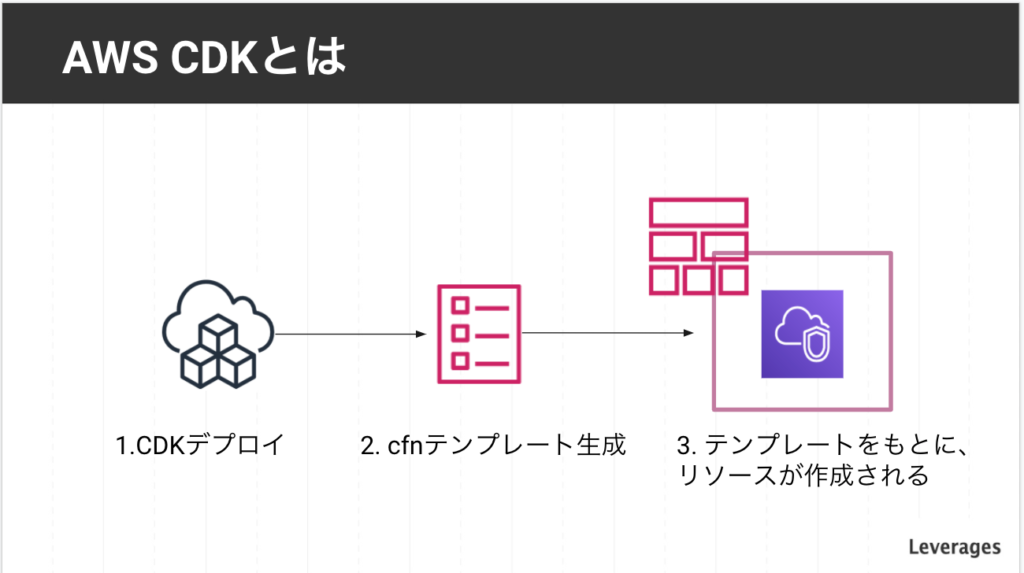
CDKとは
AWSの環境をプログラミング言語で記述できるツール。
TypeScriptやPython,Javaなど様々な言語に対応しています。
裏側ではCloudformationが使われています。
CDKを導入した理由
導入した理由は2つあります。
1つ目は、「CloudFormationからの脱却」です。
以前は、1年ほどCloudFormationでインフラを管理していました。
しかし、書き方が悪かったのもあり肥大化してしまいメンテナンス性が低く特定のメンバーしか変更出来ない状態になっていました。
そのため、Cloudformationのリファクタリングか他ツールへの乗り換えを考えていました。
2つ目は、「DevOpsの推進」です。
アプリケーションチームでもインフラの管理をできるようにすることで、開発速度やインフラのリードタイムの短縮をしたいと思っていました。
CloudFormationは、独自の記法や細かくパラメーターを設定する必要がありアプリケーションチームには学習コストが高めです。
プログラミング言語でインフラを定義できる・設定も抽象化されているCDKの方がより要件にあっていると思いました。
導入当初の感想
一言でいうと、「めちゃくちゃ楽」になりました。
プログラミング言語のため、繰り返しや関数を使ってCloudFormationと比べてコード量がかなり少なくなりました。
また、インポートしたクラスの自動補完が効くためコードを書く際のスピードがあがりました。
CloudFormation時代はリファレンスといったり来たりして、コードを書いていましたが自動補完のおかげでリファレンス見なくても雰囲気で書ける箇所もありとても楽です。
運用が辛くなった
導入からしばらく経ち、運用が辛くなりました。
理由は、「CDKの使い方が悪かった」からです。
結果、可読性が低く・修正が怖いCDKになってしまいました。
原因と対応したことを、次項から説明します。
運用が辛くなった理由1: ファイル/スタックの分割単位
ファイルとスタックの分割単位が悪かったです。
1ファイルを1アプリケーション1スタックで作成していました。
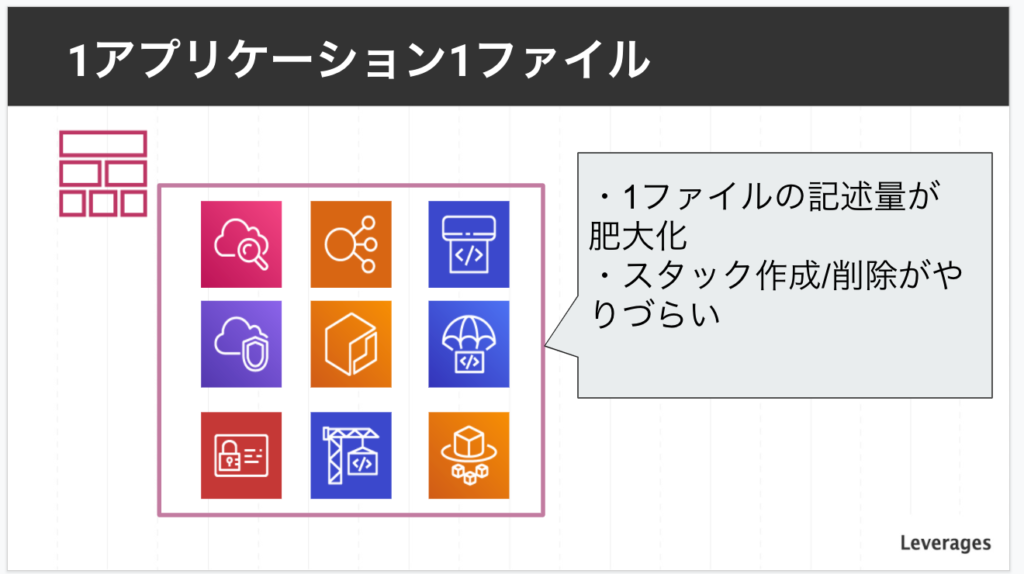
その結果、1ファイルのあたりのコード量が1000行近くなり、読みづらい状態になっていました。
また、1スタックでアプリケーションに必要なリソースをすべて作成しているためスタックの作成/削除がやりづらいです。
例えば、ECSだけ消したい場合でもスタックが同一のため、VPCやIAM,Codeシリーズなども消えてしまいます。
スタック作成や削除に時間がかかり、CDKのコードを作る時間もかかってしまいます。
「cdk deploy」する際にすべてのリソースが変更対象になります。
関係ない箇所は、変更対象にならないほうが運用上安心です。
対策としては、ライフサイクルで分割しました。
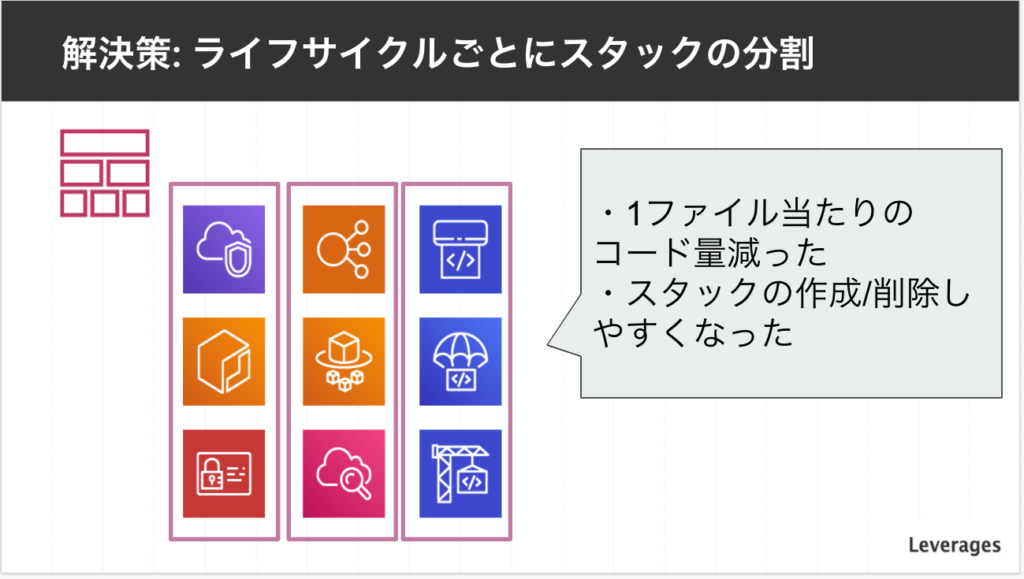
あまり変更がないVPC,ECR,IAMで1つ、ELB,ECSなどメインコンピューティング系のもので1つ、Codeシリーズなどデプロイ系のもので1つなどスタックを分割しました。
ファイルを分けることで、1ファイル当たりのコード量を減らすことが出来ました。
スタックの作成や削除もしやすくなりました。
ECSを消したいときに、VPCやIAMなどを消す必要がなくなりスタックの作成スピードが上がりました。
1スタックにしていたときだと、ECSを消すときにECRも消されました。
ECRを消すためには、イメージの削除が必要です。ECRを作成したあとは、イメージをpushし直す必要があり手間でした。
スタックを分けたことで、この手間もなくなりました。
運用が辛くなった理由2: コード量を減らすことを重視しすぎた
コード量を減らすために、長めの関数を作って複数スタックで使うということをやってしまいました。
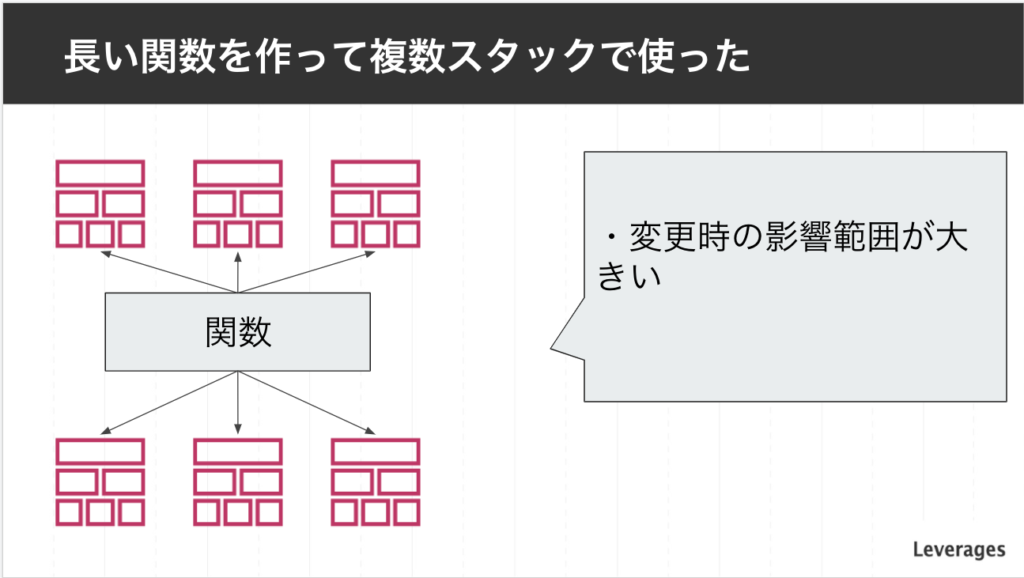
以下のような問題が発生しました
- 関数の変更時の影響範囲が大きくなった
- 設定の柔軟性が失われた
- 運用負荷があがる
設定の柔軟性が失われました。
例) Codeシリーズを作成する関数があります。スタックAだけで、CodeBuildのキャッシュを変えたいです。
しかし、共通化されているので他の箇所でも変更されてスタックAだけを変えることが出来ません。
CDKの変更を実際の環境に反映させるために、「cdk deploy」を実行する必要があります。
関数を変更した場合、関数を使っているスタック全てで「cdk deploy」を実行する必要があり手間です。
対策としては、
- ある程度似たような記述は許容する
- ライブラリ化する
High Level ConstructであったりPatternsを使えばそこまで記述量は増えないと思うので、ある程度似たような記述はあってもいいかと思います。
また、ライブラリ化しておくことで使っている側でバージョンを上げない限りは変更されないので安心です。
まとめ
CDKでもCloudformationのベストプラクティスを意識することは必要だと思います。
(ライフサイクルであったり、シンプルに書くであったり)
記述量を減らすことを意識しすぎて、デプロイ時の影響範囲が大きくなるくらいであれば、ある程度ベタ書きも許容して安心してデプロイできる状態にするのが大事だと思います。






